
What is Machine Learning?
Machine learning (ML) is a field of artificial intelligence where algorithms are trained to learn patterns and make predictions from data. In machine learning, you feed a computer system a large amount of data, and it learns to recognize patterns and make decisions without explicit programming.
You start with input data and a desired output, letting the algorithm figure out the relationship between them. You don’t explicitly tell the algorithm what to do; it learns from the data provided. In machine learning, models are trained on a dataset using various techniques. These models aim to generalize patterns and make accurate predictions on new, unseen data.
During training, the algorithm adjusts its parameters to minimize errors and improve predictions. The process is iterative, refining the model’s ability to make accurate decisions. There are different types of machine learning, including supervised learning, where the algorithm is trained on labeled data, and unsupervised learning, where the algorithm discovers patterns without labeled outputs.
Machine learning is applied in various domains, such as image recognition, natural language processing, and recommendation systems, enhancing decision-making processes across industries.
The ultimate goal of machine learning is to create models that can generalize well on unseen data, improving their ability to make accurate predictions and decisions in real-world scenarios.
Machine Learning Example
Let’s say you’re building a machine learning model for spam email detection.
In the beginning, you’d gather a dataset of emails, marking them as either spam or not spam. This labeled data helps the algorithm learn the patterns distinguishing spam from regular emails.
As you feed this data into the model, it starts recognizing features like specific words, email sender, or even the structure of the email. You don’t explicitly tell the model what features to consider; it figures that out during training.
- During the training process, the algorithm continually adjusts its parameters, fine-tuning itself to better differentiate between spam and non-spam emails. It’s like teaching the model to identify subtle cues that humans might overlook.
- Once the model is trained, you test it on new, unseen emails to see how well it generalizes. It should accurately predict whether an email is spam or not based on what it learned during training.
- Now, when you receive a new email, the machine learning model can quickly analyze it and give you a probability score of whether it’s spam or not. The model’s ability to generalize from the training data enables it to make informed decisions about unfamiliar emails.
This spam detection example illustrates how machine learning empowers systems to learn from data, adapt, and make predictions in real-world situations.
Types of Machine Learning
In machine learning, there are three primary types: supervised learning, unsupervised learning, and reinforcement learning. Let me break down each type for you.
- Supervised learning, you provide the algorithm with labeled data, meaning you give it input-output pairs. The algorithm learns to map input to output, making predictions on new, unseen data based on the patterns it learned during training.
- Unsupervised learning doesn’t have labeled outputs. Here, the algorithm explores the data without specific guidance, identifying patterns and relationships on its own. Common techniques include clustering and dimensionality reduction.
- Reinforcement learning involves training an agent to make decisions within an environment. You provide feedback in the form of rewards or penalties based on the agent’s actions, allowing it to learn optimal strategies over time.
The following diagram clearly shows the types of ML: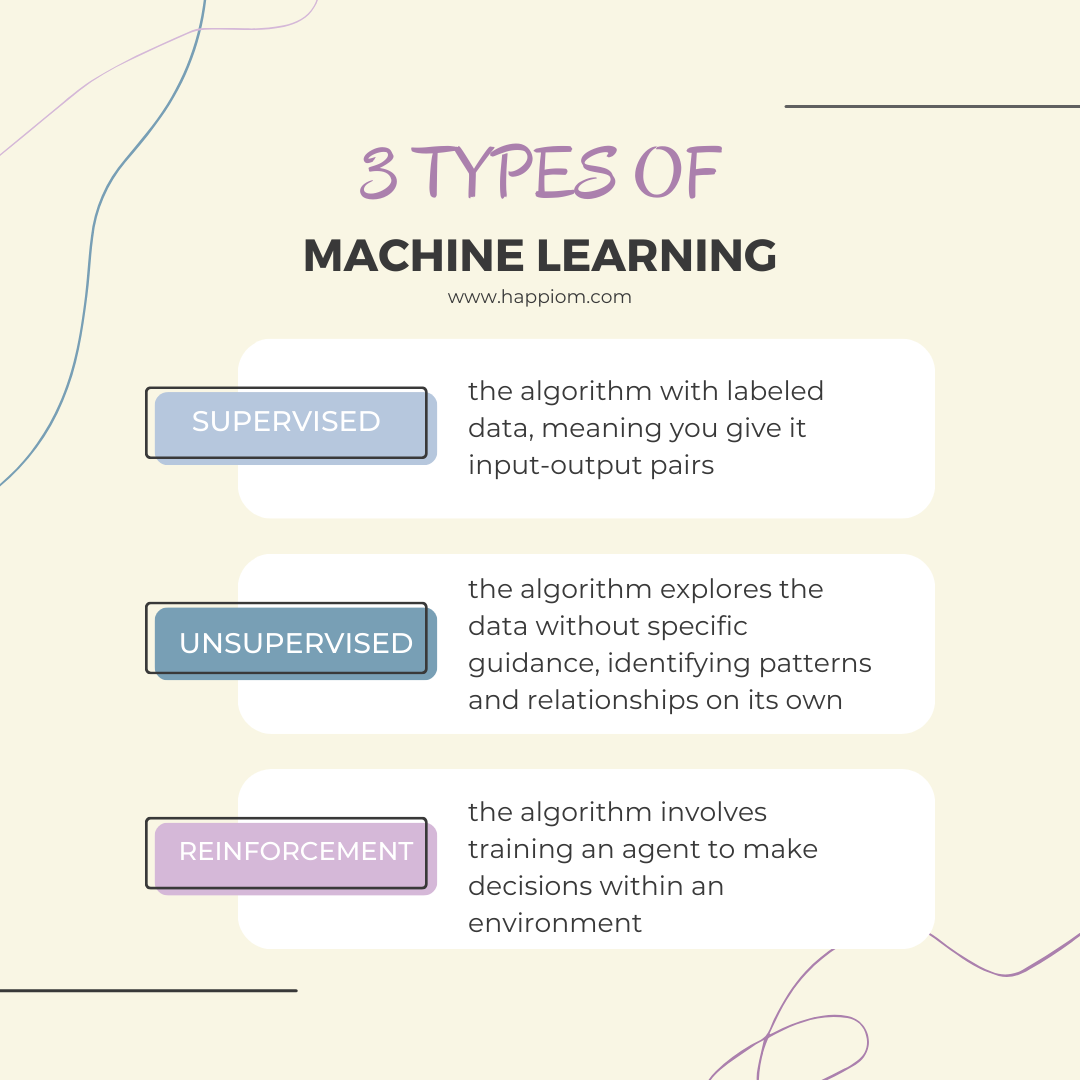
Machine Learning Process
Now, let me discuss the steps involved in a typical machine learning process!
- Data Collection – You gather a substantial amount of data relevant to your problem, ensuring it represents the scenarios you want the model to handle.
- Data Preprocessing – It involves cleaning and preparing the data. This step addresses missing values, handles outliers, and transforms the data into a suitable format for the chosen algorithm.
- Feature Engineering – Here, you select and create relevant features from the data, enhancing the model’s ability to learn patterns.
- Model Selection – You choose the type of machine learning model based on your problem – whether it’s classification, regression, or clustering – and select an algorithm that suits your data and objectives.
- Training the Model – This step involves feeding the algorithm with the labeled data and letting it adjust its parameters to learn the underlying patterns. The model continuously refines itself to improve its predictions.
- Model Evaluation and Deployment – After training, you assess the model’s performance on new, unseen data. If it meets your criteria, you deploy it to make predictions or decisions in real-world applications.
These steps encapsulate the process of implementing machine learning, offering a structured approach to developing models that can learn from data and generalize well on unseen instances.
Frequently Asked Questions (FAQs) about ML
1. What is machine learning?
Machine learning is a field of artificial intelligence where algorithms are trained to learn patterns from data and make predictions or decisions without explicit programming.
2. How does machine learning work?
It works by feeding a computer system a large dataset, allowing the algorithm to learn patterns and relationships within the data, enabling it to make informed decisions or predictions.
3. What are the types of machine learning?
There are three main types: supervised learning (labeled data), unsupervised learning (unlabeled data), and reinforcement learning (learning through rewards and penalties in an environment).
4. What is the difference between supervised and unsupervised learning?
Supervised learning involves labeled data for training, while unsupervised learning explores data without labeled outputs, identifying patterns and relationships independently.
5. Can you provide an example of machine learning in everyday life?
Spam email detection is an example where machine learning is used to analyze patterns in emails to distinguish between spam and non-spam messages.
6. What is overfitting in machine learning?
Overfitting occurs when a model learns the training data too well, capturing noise and outliers, making it perform poorly on new, unseen data.
7. How do you evaluate the performance of a machine learning model?
Common evaluation metrics include accuracy, precision, recall, and F1 score, which assess different aspects of the model’s performance based on its predictions.
8. What is the role of feature engineering in machine learning?
Feature engineering involves selecting and creating relevant features from the data, enhancing the model’s ability to learn and make accurate predictions.
9. Can machine learning models be biased?
Yes, machine learning models can exhibit bias if the training data is not representative. Careful consideration of data sources and preprocessing is essential to mitigate bias.
10. How is machine learning used in business?
Machine learning is employed in business for various applications, including customer segmentation, fraud detection, demand forecasting, and personalized recommendations, enhancing decision-making processes.